

Bridging the client-server boundary – An experiment in architectures for next-generation web applications
This article is the first of a series in which I design and experiment with a new mechanism for building tomorrow’s web applications. Specifically, I’m interested in blurring the gap between client & server, such that both parties are unaware of their relationship to the other.
You can
The problem
Consider the following very common scenario where a web page signs up a new user based on their email address:
- the human enters an email address and presses the Sign Up button
- the browser posts the email address to your server
- the server receives the email, runs it through the business logic and then saves in the database
- the server returns (unloads the call stack), sending a 200-OK message back to the web browser
- the web browser receives the successful message and displays a message saying as much
In graphic terms, the communication flow is a little like this:

This is all well and good, but now consider that, as part of the server’s business logic, the email address is compared with existing registrations and deemed to be a duplicate. It is okay to save duplicates in our database, but we want to make sure that the human didn’t actually mean to Sign In to their existing account. So, the communication now has an extra round-trip:
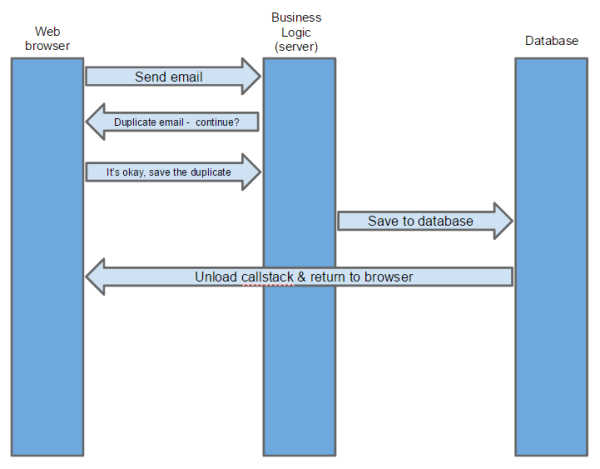
This is pretty easy to draw on a diagram, but in practice, coding it up involves a lot more function points:
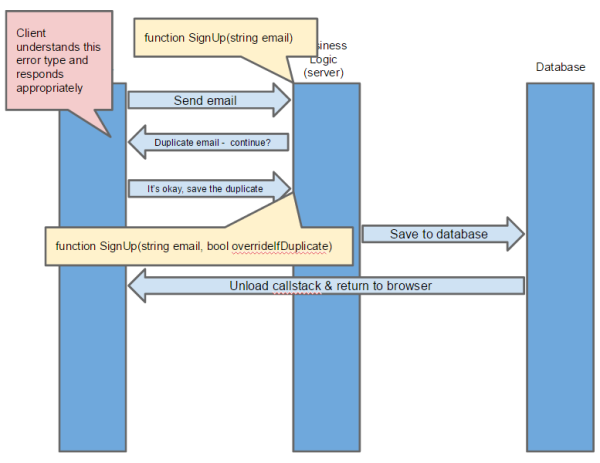
As the callouts in the diagram above show, our intrepid developer needs to write extra code to:
- listen for the ‘duplicate email’ message from the server and display a confirmation box to the human asking if they’d like to continue even though it is a duplicate email
- write an additional API method which accepts the selection that the user made. In actual practice, this may be the same function method with an optional override, but the point is that it needs to be accommodated
To get technical, this is what our SaveSignup() method might look like (in the business logic layer):
public void SaveSignUp(string email, bool? overrideIfDuplicate){ var emailAlreadyExists = MyEmailServer.EmailAlreadyExists(email); if (emailAlreadyExists && !overrideIfDuplicate) throw new DuplicateEmailException("This email already exists"); // Save MySignUpService.Save(email); }
Keep in mind that this method would be called twice – the first time with no overrideIfDuplicate parameter, and then the second time where the user has set it to ‘true’.
Further to this, when the server confirms whether or not the duplicate should be saved, it implicitly assumes that the human is still there at the other end, ready to answer. What if the existing database has 1 billion emails already and the duplication check takes 20 seconds – should we expect a human to wait this long for what they perceive to be a simple form submission? Nup.
The answer
So this is the goal of my article – let’s see if we can develop an architecture like this:

This diagram was a little hard to draw, so please bear with me. What I’m trying to convey is:
- the initial saving of the sign up form returns immediately, and the human can continue with their workflow (including leaving our website altogether)
- when the server detects a duplicate, it doesn’t specifically fire this back at the client (although in this diagram, the client does answer it). You might initially think of this like an event, but in fact it is a pause in execution
A pause in execution
A pause in execution – and this will become the crux in my architecture. Ultimately, I want the aforementioned function to be rewritten like this:
public void SaveSignUp(string email){ var emailAlreadyExists = MyEmailServer.EmailAlreadyExists(email); var bridge = new MyFancyNewArchitectureMessenger(); if (emailAlreadyExists && !bridge.Listen("This email has already been registered. Are you sure you wish to continue?")) return; // Save MySignUpService.Save(email); }
In this rewritten example, we don’t have to write extra parameters to accept extra logic. Instead, as questions arise, we simply ask them in what appears to be a synchronous manner (of course, the actual execution can’t be synchronous, but I want it to appear that way).
If this doesn’t look like much of a difference to you, consider this more real-world example with more logical paths:
The current way…
public void SaveSignUp(string email, bool overrideIfDuplicate, bool? inviteAFriend, string friendsEmailAddress){ // Check if the email already exists, or if the user has agreed to store it anyway var emailAlreadyExists = !regex.IsMatch(email); if (emailAlreadyExists && !overrideIfDuplicate) throw new DuplicateEmailException("This email already exists"); // TODO: save to database // Check if they want to invite a friend? if (!inviteAFriend.HasValue)) throw new InviteAFriendException("Would you like to invite a friend?"); // They've agreed to invite a friend? if (inviteAFriend.Value && !string.IsNullOrWhiteSpace(friendsEmailAddress)){ // TODO: save friend's email address to database } }
My new way…
public void SaveSignUp(string email){ var bridge = Dependency.Resolve<IBridge>(); // Confirm the email address? if (!regex.IsMatch(email)) { // Confirm with user? if (!await bridge.Listen(new YesNoPrompt("Invalid email", "Your email is not a valid format. Are you sure you wish to save it?"))) { return; } } // TODO: save to database // Would they like to invite a friend? if (await bridge.Listen(new YesNoPrompt("Invite friend", "Would you like to invite a friend?"))) { var friendsEmail = await bridge.Listen(new Readline("Invite friend", "What is your friend's email address?")); // TODO: save to database } }
Although the two code examples above are similar in length, the new architecture is much easier to develop because it is built in a linear fashion:
- With the former, our fearless developer would have also had to do a lot of work on the client such as passing up new variables and responding to different exception types.
- With the latter, our developer simply asks questions of the bridge and waits for a response. They have no knowledge or concern for how the questions are being asked.
Building a bridge between the client & server
For version one of my bridge, I decided to use a combination of now somewhat-old technologies:
- SignalR. SignalR uses websockets and this allows me to push my bridge messages down to the client (I also use it to push messages from the client to the server, although this could equally have been done with a regular HTTP post).
- Microsoft’s new async/await construct. Because version one of the bridge uses loops and polling, I use async/await to move the processing to a different thread – thereby freeing up IIS to server up other requests.
Let’s look at the code:
private async Task<T> Listen<T>(IBridgeMessage<T> msg){ // Poll the cache, waiting for a result var cache = new CacheManager<IBridgeMessage<T>>(); IBridgeMessage<T> result = null; // Cancel after a few seconds var cancel = new CancellationTokenSource(); cancel.CancelAfter(TimeSpan.FromSeconds(20)); // Version one - poll the cache in a loop to check for our return await Task.Factory.StartNew(() => { while (true) { // Listen to see if we've timed out if (cancel.IsCancellationRequested) break; // Check the cache - the cache matches based on the the msg.MessageID property result = cache.Load(msg, null); if (result != null) break; // Wait a wee while before checking again System.Threading.Thread.Sleep(100); } }, cancel.Token); // Return if (result == null) { NotifyCancelled(msg.MessageID); return default(T); } return result.Result; }
As you can see, the code essentially just loops, checking for a variable in our cache (which our client later populates – see below). Now, I know that this is not very elegant – obviously the server is still using resources even when ‘idle’, and clearly this method wouldn’t scale well once we had a few thousand concurrent users. But it’s a good start for version one.
As I mentioned, the code will repeatedly check our cache for a return token, which is inserted by the client like this:
public void Answer(string jsonEncodedResult) { if (String.IsNullOrWhiteSpace(jsonEncodedResult)) return ; // Deconstruct the entities var jToken = (JToken)Newtonsoft.Json.JsonConvert.DeserializeObject(jsonEncodedResult); var requestedTypeName = jToken.Value<string>("TypeName"); // Because they were serialized from an abstract class (BaseTemplateItem), Newtonsoft can't automatically cast them to their types as they're just a collection of {name:value} pairs // So, we need to iterate through and cast them ourselves var itemTypes = System.Reflection.Assembly.GetAssembly(typeof(IBridgeMessage)).GetTypes().Where(x => x.IsSubclassOf(typeof(BaseBridgeMessage))).ToList(); var thisType = itemTypes.FirstOrDefault(x => x.Name == requestedTypeName); if (thisType == null) return; // Need to cast to its appropriate type var item = Newtonsoft.Json.JsonConvert.DeserializeObject(jsonEncodedResult, thisType); // Just pop the result in our (shared) cache, and the listeners above will extract it var cache = new CacheManager<ICachable>(); cache.Save((ICachable)item); }
The bulk of this method is actually to do with parsing a JSON result back to our message type – in fact, the only part we’re interested in now is the last two lines where we store the result back in our cache, ready for our aforementioned loop to pick it up in the Listen() method.
Proof of concept complete – what’s next for version two?
This code has established a semantic framework for how I want the code to work. Specifically:
- code is written in an apparently synchronous manner
- code is written with no regard for who or what it is interacting with – no fiddling around with matching client-side API calls to server side methods
- semantically, our code appears to pause in execution when a question is asked of the bridge. Once the bridge responds, execution continues in a linear fashion. Compare this with current methods, where the entire http request is sent again
However, there is one glaring problem which prevents this code from being used in real-world scenarios and that is to do with how we store and retain state…
Storing and resuming state
As we have seen, not only does our Listen() method hog a new thread, it essentially holds the entire call stack in memory while it waits. Although I haven’t tested it, I’m certain this will not scale well.
Unfortunately though, in order for my code to be semantically synchronous, I need some mechanism for both storing state before our call to Listen(), and restoring it after we get a response.
And by ‘state’, I include a variety of things:
- the call stack
- incoming parameters to our current function (and those of the calling function, and those of that calling function….and so on, up the call stack)
- if we are building a web application, I need access to things like the Session and Cookies variables
- any configuration values (e.g. stored in web.config or app.config files)
Replacing the way I store and resume state will be the focus of version two of this architecture. At this point, I don’t know how I’m going to do it, but things worth pursuing are:
- serializing and storing the call stack in the database
- can .Net’s reflection classes allow me to resume the call stack from a specific point?
- perhaps .Net is simply not capable of doing something like this, and something like Node.js would work better
- on that note, would a scripting language (such as Node) allow me to literally build and execute code on the fly?
- and I should actually do some benchmarks to see just how poorly performing the existing version one code is – perhaps it would actually suffice for a moderately-sized web application after all?
In addition, I’d like to extend the implementation to provide a different bridge. We currently use SignalR to communicate with a web-based client, but because our bridge is abstracted via an interface, we could easily write a new Bridge which (for example) sent the user an email with a link to confirm/decline an action (think about that for a second – the code would still just be waiting on the Listen() method, even though behind the scenes our bridge is firing emails around the world, potentially over the course of a few hours or even days. That is pretty cool).
Download the example code
I’ve built a working prototype of this version one architecture, which you can download here. Because I intend to extend the architecture, there is a lot of extra stuff with the result being that it is a lot more complicated than typical tutorials. In particular:
- I’m using Microsoft Unity for my dependency injection
- the client-side javascript is architected using RequireJS
- The CSS is written using LessCss and a Task Runner plugin to run Gulp. Of course, you shouldn’t need to change the CSS, but just so you know…
- the project was written in VS2013
- I included all the Nuget binaries, so it is quite a big download but hopefully it means you can get up and running quicker
Okay, good luck and have fun. If you have any ideas on how I can progress this, best to get me on Twitter – @benliebert




